NLP Binary Classification of tweets
Classification model to determine if tweets are about a disaster or not.
I am an Industrial Engineer utilizing the power of python to gain deeper insights in data.
I am currently learning Deep learning with TensorFlow
Wanted to share my steps in predicting if a random tweet was about a current disaster or if it was just a tweet, not about a disaster. This model was trained on the Kaggle Disaster Tweet dataset. It also uses a TensorFlow Hub pretrained universal sentence encoder, USE in a Sequential Model.
First loaded the needed libraries and imported Kaggle dataset
# Import libraries
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
from wordcloud import WordCloud
# Import data
train_df = pd.read_csv("/kaggle/input/nlp-getting-started/train.csv")
test_df = pd.read_csv("/kaggle/input/nlp-getting-started/test.csv")
train_df.head()

Shuffled and split the data
# Shuffle training dataframe
train_df_shuffled = train_df.sample(frac=1, random_state=42)
train_df_shuffled.head()
# Use train_test_split to split training data into training and validation sets
train_sentences, val_sentences, train_labels, val_labels = train_test_split(train_df_shuffled["text"].to_numpy(),
train_df_shuffled["target"].to_numpy(),
test_size=0.1,
random_state=42)
# Create sentences and labels
whole_train_sentences = train_df_shuffled['text'].to_numpy()
whole_train_labels = train_df_shuffled['target'].to_numpy()
len(whole_train_sentences) , len(whole_train_labels)
Created the Keras Layer using the pretrained universal sentence encoder.
# Create a Keras layer using the USE pretrained layer from tensorflow hub
sentence_encoder_layer = hub.KerasLayer("https://tfhub.dev/google/universal-sentence-encoder/4",
input_shape=[],
dtype=tf.string,
trainable=False,
name="USE"
)
Created a Sequential model
# Create model using the Sequential API
model = tf.keras.Sequential([
sentence_encoder_layer,
layers.Dense(64 , activation ='relu'),
layers.Dense(1, activation="sigmoid")
])
# Compile model
model.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.legacy.Adam(),
metrics=["accuracy"])
# Train a classifier on top of pretrained embeddings
model_history =model.fit(whole_train_sentences,
whole_train_labels,
epochs=5,
validation_data=(val_sentences, val_labels))

Make predictions
# Make predictions with the model
pred_probs = model.predict(test_df['text'].to_numpy())
Submitted my predictions in the Kaggle Competition. It just beat the AutoML Benchmark.

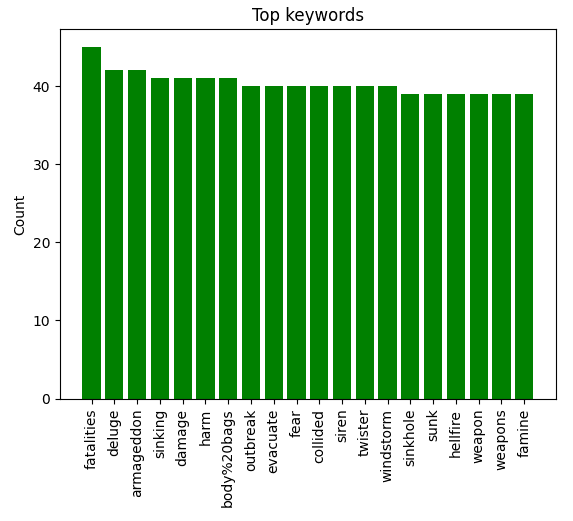
I also created some visuals to view the keywords in the tweet data.


I also used the TensorFlow projector tool to visualize the embeddings. It produced a neat clustering a related words.

You can find the Kaggle notebook here