D
I am an Industrial Engineer utilizing the power of python to gain deeper insights in data.
I am currently learning Deep learning with TensorFlow
This Kaggle dataset contains soil characteristics, used to recommend what type of farm crop to plant in that soil with a machine learning classification model.
I created a baseline by comparing the performance of 5 different classification models, measuring accuracy.
First setup, a dictionary of models.
# Put models in a dictionary
models = {"KNN": KNeighborsClassifier(),
"Logistic Regression": LogisticRegression(),
"Random Forest": RandomForestClassifier(),
"GradientBoost": GradientBoostingClassifier(),
"GaussianNB": GaussianNB(),
}
# Create function to fit and score models
def fit_and_score(models, X_train, X_test, y_train, y_test):
"""
Fits and evaluates given machine learning models.
models : a dict of different Scikit-Learn machine learning models
X_train : training data
X_test : testing data
y_train : labels assosciated with training data
y_test : labels assosciated with test data
"""
# Random seed for reproducible results
np.random.seed(42)
# Make a list to keep model scores
model_scores = {}
# Loop through models
for name, model in models.items():
# Fit the model to the data
model.fit(X_train, y_train)
# Evaluate the model and append its score to model_scores
model_scores[name] = model.score(X_test, y_test)
return model_scores
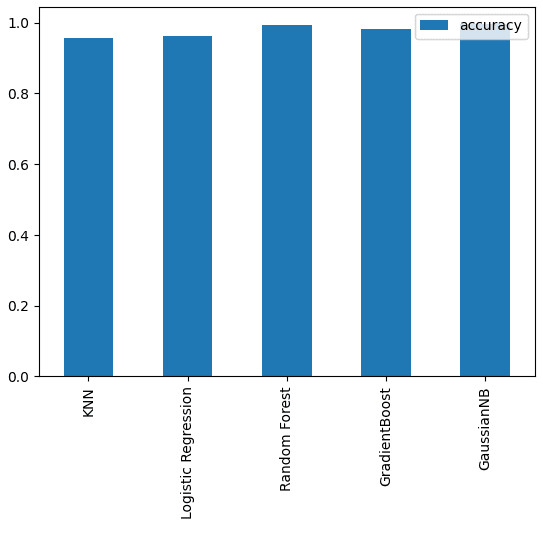
{'KNN': 0.9568181818181818,
'Logistic Regression': 0.9636363636363636,
'Random Forest': 0.9931818181818182,
'GradientBoost': 0.9818181818181818,
'GaussianNB': 0.9954545454545455}
The baseline scores show the Gaussian and Random Forest models performing the best.

Next steps of the model will be selection of either Gaussian or Random Forest models and performing cross validation grid search hyper parameter tuning.